Java中的集合类主要可以分为两大体系:
- Collection体系
- Map体系
集合类中的主要继承与实现关系可以归纳为以下两图(蓝色为类,绿色为接口,红色为抽象类)
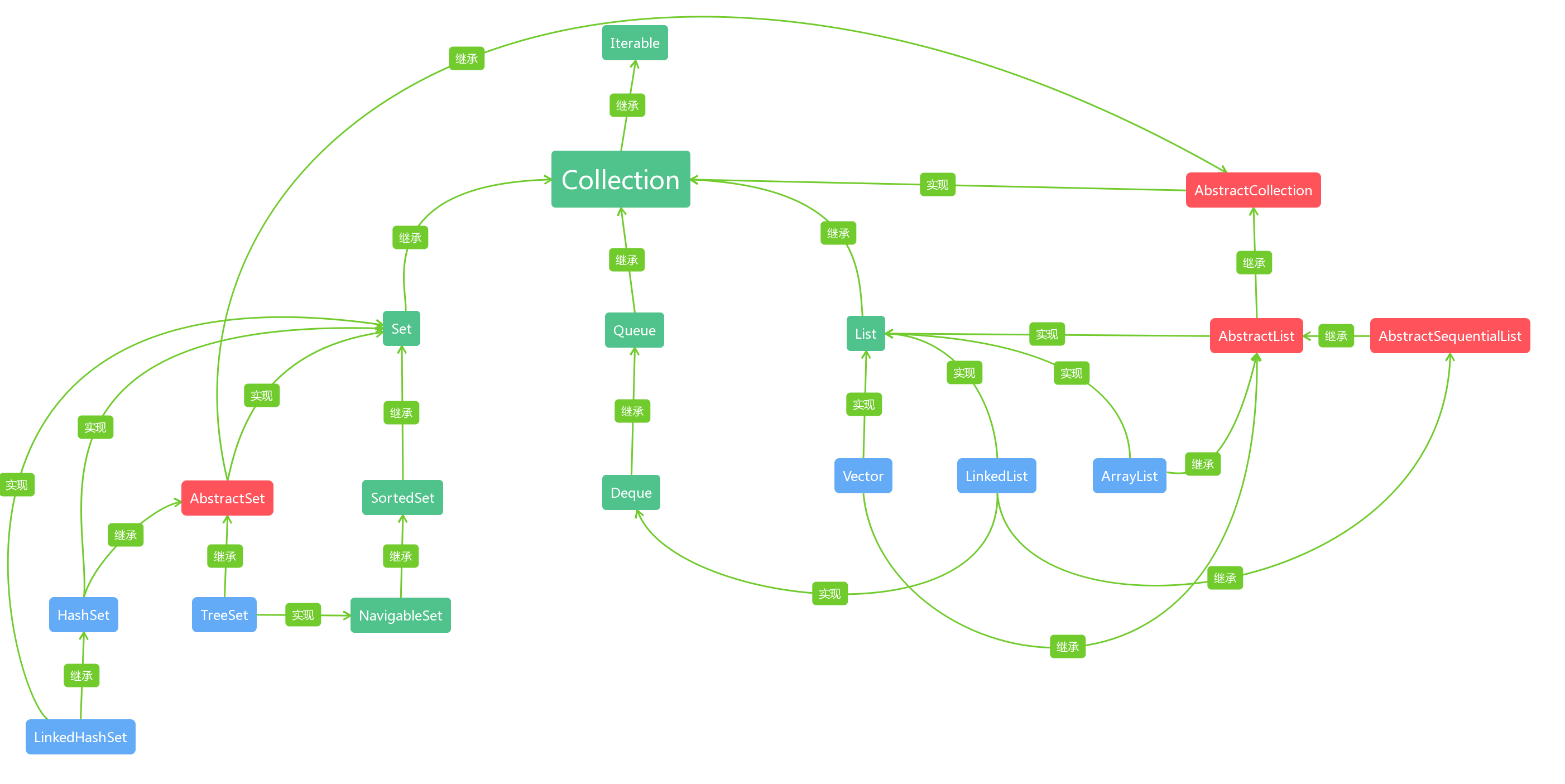
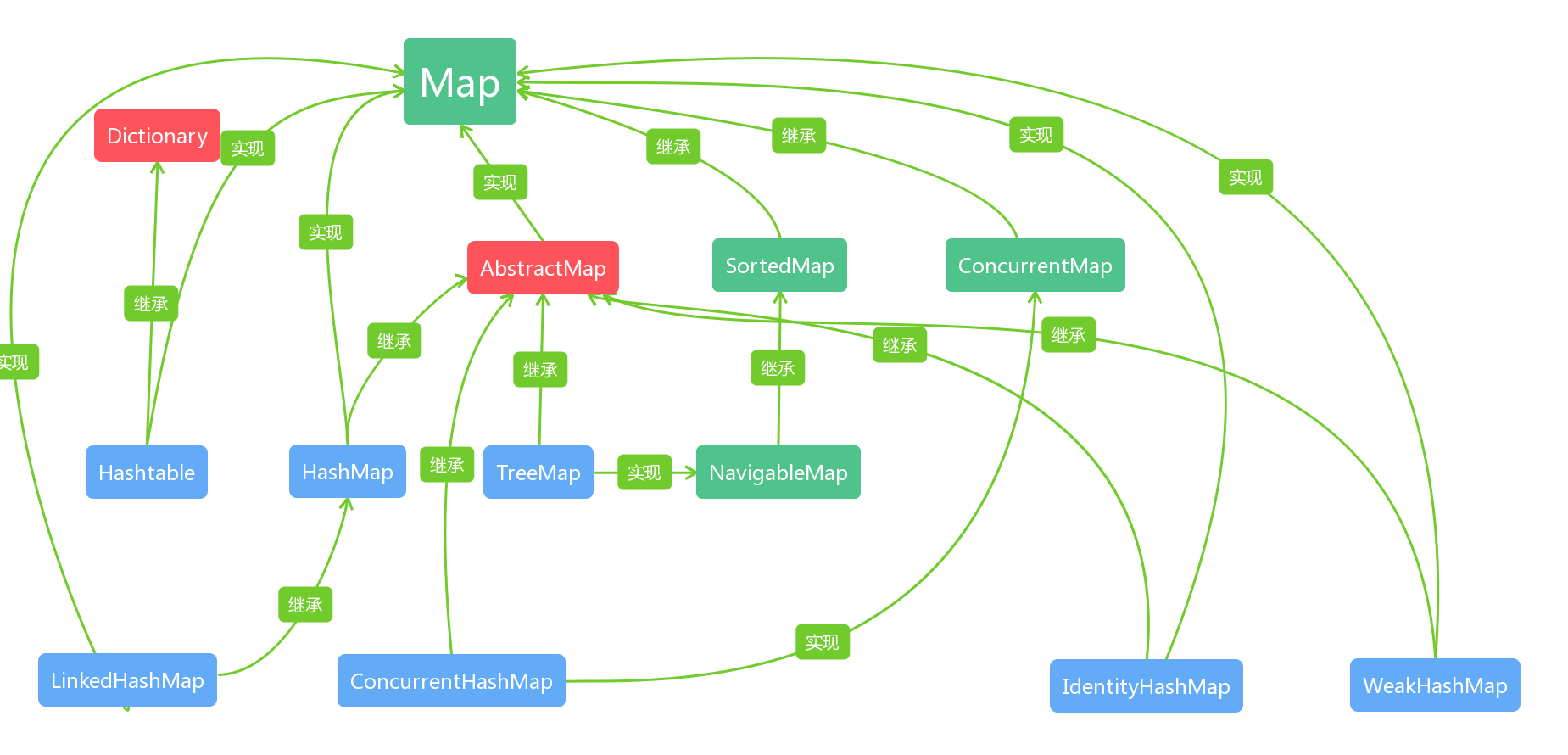
一、Collection系集合
1、List系集合
①List接口源码
我们可以通过上面的图片看出,List系的集合Vector、LinkedList、ArrayListd都是对List接口的实现,我们就先打开List接口的源码,可以看出,List接口除了定义了类似add、remove等List的操作之外,还提供了sort、spliterator等的默认实现。
从jdk8开始,java允许我们在接口中定义static方法与default方法并给出其默认实现。
public interface List<E> extends Collection<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean addAll(int index, Collection<? extends E> c);
boolean removeAll(Collection<?> c);
boolean retainAll(Collection<?> c);
default void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final ListIterator<E> li = this.listIterator();
while (li.hasNext()) {
li.set(operator.apply(li.next()));
}
}
@SuppressWarnings({"unchecked", "rawtypes"})
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
void clear();
boolean equals(Object o);
int hashCode();
E get(int index);
E set(int index, E element);
void add(int index, E element);
E remove(int index);
int indexOf(Object o);
int lastIndexOf(Object o);
ListIterator<E> listIterator();
ListIterator<E> listIterator(int index);
List<E> subList(int fromIndex, int toIndex);
@Override
default Spliterator<E> spliterator() {
if (this instanceof RandomAccess) {
return new AbstractList.RandomAccessSpliterator<>(this);
} else {
return Spliterators.spliterator(this, Spliterator.ORDERED);
}
}
static <E> List<E> of() {
return ImmutableCollections.List0.instance();
}
static <E> List<E> of(E e1) {
return new ImmutableCollections.List1<>(e1);
}
static <E> List<E> of(E e1, E e2) {
return new ImmutableCollections.List2<>(e1, e2);
}
static <E> List<E> of(E e1, E e2, E e3) {
return new ImmutableCollections.ListN<>(e1, e2, e3);
}
static <E> List<E> of(E e1, E e2, E e3, E e4) {
return new ImmutableCollections.ListN<>(e1, e2, e3, e4);
}
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5) {
return new ImmutableCollections.ListN<>(e1, e2, e3, e4, e5);
}
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5, E e6) {
return new ImmutableCollections.ListN<>(e1, e2, e3, e4, e5,
e6);
}
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7) {
return new ImmutableCollections.ListN<>(e1, e2, e3, e4, e5,
e6, e7);
}
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8) {
return new ImmutableCollections.ListN<>(e1, e2, e3, e4, e5,
e6, e7, e8);
}
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8, E e9) {
return new ImmutableCollections.ListN<>(e1, e2, e3, e4, e5,
e6, e7, e8, e9);
}
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8, E e9, E e10) {
return new ImmutableCollections.ListN<>(e1, e2, e3, e4, e5,
e6, e7, e8, e9, e10);
}
@SafeVarargs
@SuppressWarnings("varargs")
static <E> List<E> of(E... elements) {
switch (elements.length) { // implicit null check of elements
case 0:
return ImmutableCollections.List0.instance();
case 1:
return new ImmutableCollections.List1<>(elements[0]);
case 2:
return new ImmutableCollections.List2<>(elements[0], elements[1]);
default:
return new ImmutableCollections.ListN<>(elements);
}
}
@SuppressWarnings("unchecked")
static <E> List<E> copyOf(Collection<? extends E> coll) {
if (coll instanceof ImmutableCollections.AbstractImmutableList) {
return (List<E>)coll;
} else {
return (List<E>)List.of(coll.toArray());
}
}
}
在这里仅简单讲一下List接口中对排序的实现
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
我们可以看到,List的sort方法主要是先将List元素转换为数组,然后调用Arrays的sort方法实现的,我们再进入Arrays的sort方法看一下。
public static <T> void sort(T[] a, Comparator<? super T> c) {
if (c == null) {
sort(a);
} else {
if (LegacyMergeSort.userRequested)
legacyMergeSort(a, c);
else
TimSort.sort(a, 0, a.length, c, null, 0, 0);
}
}
曾经遇到过一个面试题,问的是java默认的排序方式是什么,当初回答的是快速排序,但在这里可以看到,它使用的主要是TimSort,至于什么是TimSort,我们在这里可以看作一种基于归并排序和插入排序的混合排序方式,其主要的算法实现我们在之后的文章中再作叙述。
②ArrayList源码
从ArrayList的源码可以看出,当我们初始化ArrayList时,若未对ArrayList进行容量的初始化,默认的ArrayList大小为10。
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
在ArrayList中,使用elementData数组保存存入ArrayList中的数据,使用size存储当前存入数据的数量。
transient Object[] elementData; // non-private to simplify nested class access
private int size;
ArrayList的初始化有多种方式,我们先就以下这种初始化方法进行分析
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
这时一种比较简单的初始化方式,只需要在初始化时为ArrayList设置初始大小。然后elementData对象就会初始化为该大小的数组。当initialCapacity为0时,就会直接使用预先初始化好的一个空数组将elementData进行初始化操作。
动态扩容
在我们添加的数据超出elementData的大小时,就需要对elementData进行动态扩容,而动态扩容的操作自然是发生在add方法中。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
可以看到,在添加数据前,执行了ensureCapacityInternal方法,其目的是检测当前的数据数量是否超过数组大小,如果超过,则进行扩容。其主要判断代码如下。
private static int calculateCapacity(Object[] elementData,int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA){
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData,minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
可以看到,在我们判断到容量超过数组大小时,又调用了grow方法进行扩容操作。
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
可以看到,在进行扩容时,执行的操作是int newCapacity = oldCapacity + (oldCapacity >> 1);,其实际意义上相当于是int newCapacity = oldCapacity * 1.5;。也就是每次扩容就讲数组的最大容量设置为原容量的1.5倍。
即在默认容量为10的基础上,插入第11个数据时,容量扩大为15.在插入第16个数据时,容量扩大为22。
③LinkedList源码
LinkedList的实现主要依赖双向链表,LinkedList记录链表的头节点与尾节点,同样使用size记录当前链表中的节点数量。
transient int size = 0;
transient Node first;
transient Node last;
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
而由于LinkedList不存在动态扩容问题,故其add方法也是传统的链表节点的增添操作。
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node l = last;
final Node newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
④Vector源码
Vector的源码实现与ArrayList相差不大,它和ArrayList的差别主要体现再两个方面:
Vector中对增删等操作均进行了线程同步处理(添加synchronized修饰符)
public synchronized boolean add(E e) { modCount++; add(e, elementData, elementCount); return true; } public synchronized E get(int index) { if (index >= elementCount) throw new ArrayIndexOutOfBoundsException(index); return elementData(index); }- 在Vector中的扩容操作,相对应的操作是
int newCapacity = oldCapacity + (oldCapacity >> 1),每次扩容为原本的1.5倍。而Vector中的扩容则是int newCapacity = oldCapacity + ((capacityIncrement > 0) ?capacityIncrement : oldCapacity);,即如果指定了增长量,则扩容相应的增长量大小,否则,则扩容为原来的两倍。
⑤线程安全性
无论是ArrayList还是LinkedList都是线程不安全的。
对于ArrayList来说,在进行多线程操作添加数据时,可能会出现如下情况:
(1)ArrayList中已添加了9个数据,此时未进行过扩容,最大存入10个数据,size变量为9.
(2)A线程进行判断,判断结果还有可插入的空间,无需进行扩容。同时B线程也进行了判断,判断结果也是不需要扩容。
(3)A线程数据进行了插入size位置,此时空间满,size更改为10。
(4)B线程进行插入操作,插入size位置,但由于未进行扩容,故不存在下标为10的空间,插入操作越界,插入失败。
LinkedList同样时如此,当进行add操作时,可能存在两个线程中添加的数据指向的prev节点为同一个节点的情况。初次之外,LinkedList的其他操作也存在类似问题。
使用线程安全的List主要有以下两个方法:
(1)使用synchronized关键字进行限制。
(2)使用Collections.synchronizedList(),如下
List> data=Collections.synchronizedList(new ArrayList>());
而Vector则是线程安全的,它的线程安全主要是由于它的synchronized修饰原因,但也因为强制进行同步,所以它的性能相较于线程不安全的ArrayList较差。
但如果我们要实现线程安全的存储,到底是Vector性能更高,还是Collections.synchronizedList处理后的ArrayList性能更高呢?
我们之前看了Vector,它与ArrayList的区别就是在方法上加锁,我们再来看一下Collections.synchronizedList。
public static <T> List<T> synchronizedList(List<T> list) {
return (list instanceof RandomAccess ?
new SynchronizedRandomAccessList<>(list) :
new SynchronizedList<>(list));
}
可以看出它返回的是一个SynchronizedList对象,我们再进入SynchronizedList的实现中看一下。
SynchronizedList(List<E> list) {
super(list);
this.list = list;
}
SynchronizedList(List<E> list, Object mutex) {
super(list, mutex);
this.list = list;
}
public E set(int index, E element) {
synchronized (mutex) {return list.set(index, element);}
}
public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}
public E remove(int index) {
synchronized (mutex) {return list.remove(index);}
}
可以看出,SynchronizedList进行的是一种类似代理的委托服务,实际依旧是调用我们传进来的List的方法,只不过在它的外层进行了代码块的加锁。而Vector是进行的是方法的加锁。
因为有了这一层的委托加锁,所以Vector的效率会略高于Collections.synchronizedList处理后的ArrayList。
2、Set系集合
①Set接口源码
相较于List接口,Set接口的区别不大,仅仅是没有了sort等方法,我们也可以看到,Set作为无重复的集合,对重复元素的判断等操作也是交给子类来实现的。
public interface Set<E> extends Collection<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean retainAll(Collection<?> c);
void clear();
boolean equals(Object o);
int hashCode();
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT);
}
static <E> Set<E> of() {
return ImmutableCollections.Set0.instance();
}
static <E> Set<E> of(E e1) {
return new ImmutableCollections.Set1<>(e1);
}
static <E> Set<E> of(E e1, E e2) {
return new ImmutableCollections.Set2<>(e1, e2);
}
static <E> Set<E> of(E e1, E e2, E e3) {
return new ImmutableCollections.SetN<>(e1, e2, e3);
}
static <E> Set<E> of(E e1, E e2, E e3, E e4) {
return new ImmutableCollections.SetN<>(e1, e2, e3, e4);
}
static <E> Set<E> of(E e1, E e2, E e3, E e4, E e5) {
return new ImmutableCollections.SetN<>(e1, e2, e3, e4, e5);
}
static <E> Set<E> of(E e1, E e2, E e3, E e4, E e5, E e6) {
return new ImmutableCollections.SetN<>(e1, e2, e3, e4, e5,
e6);
}
static <E> Set<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7) {
return new ImmutableCollections.SetN<>(e1, e2, e3, e4, e5,
e6, e7);
}
static <E> Set<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8) {
return new ImmutableCollections.SetN<>(e1, e2, e3, e4, e5,
e6, e7, e8);
}
static <E> Set<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8, E e9) {
return new ImmutableCollections.SetN<>(e1, e2, e3, e4, e5,
e6, e7, e8, e9);
}
static <E> Set<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8, E e9, E e10) {
return new ImmutableCollections.SetN<>(e1, e2, e3, e4, e5,
e6, e7, e8, e9, e10);
}
@SafeVarargs
@SuppressWarnings("varargs")
static <E> Set<E> of(E... elements) {
switch (elements.length) { // implicit null check of elements
case 0:
return ImmutableCollections.Set0.instance();
case 1:
return new ImmutableCollections.Set1<>(elements[0]);
case 2:
return new ImmutableCollections.Set2<>(elements[0], elements[1]);
default:
return new ImmutableCollections.SetN<>(elements);
}
}
@SuppressWarnings("unchecked")
static <E> Set<E> copyOf(Collection<? extends E> coll) {
if (coll instanceof ImmutableCollections.AbstractImmutableSet) {
return (Set<E>)coll;
} else {
return (Set<E>)Set.of(new HashSet<>(coll).toArray());
}
}
}
通过最上面的图我们可以看出,Set接口的最终实现类中都包含了对AbstractSet的继承,而通过源码我们可以看到在AbstractSet类中仅仅完成的是对equals、hashcode、removeAll方法的实现。
public boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Set))
return false;
Collection<?> c = (Collection<?>) o;
if (c.size() != size())
return false;
try {
return containsAll(c);
} catch (ClassCastException unused) {
return false;
} catch (NullPointerException unused) {
return false;
}
}
public int hashCode() {
int h = 0;
Iterator<E> i = iterator();
while (i.hasNext()) {
E obj = i.next();
if (obj != null)
h += obj.hashCode();
}
return h;
}
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
boolean modified = false;
if (size() > c.size()) {
for (Object e : c)
modified |= remove(e);
} else {
for (Iterator<?> i = iterator(); i.hasNext(); ) {
if (c.contains(i.next())) {
i.remove();
modified = true;
}
}
}
return modified;
}
②TreeSet源码
通过图我们可以看到,TreeSet除了继承AbstractSet之外,还实现了NavigableSet接口,而NavigableSet接口继承了SortedSet接口。
以此扩展,直接看第二张图中的Map系集合,其中的TreeMap除了继承AbstractMap之外,还实现了NavigableMap接口,而NavigableMap接口继承了SortedMap接口。
先说以下SortedSet接口,其中提供的我们需要实现的方法有以下几个:
//SortedSet提供的方法:
comparator()//自己定义比较器,对内部元素排序
first()//第一个元素
headSet(E e)//e之前的元素,不包括e
last()//最后一个元素
spliterator()//Java8新增,生成Spliterator接口,有点类似nio里的selector
subSet(E e1, E e2)//e1和e2之间的元素
tailSet(E e)//e之后的元素,包括e
简单说,SortedSet的作用就是告诉我们要实现排序的Set需要实现的方法。
而NavigableSet,则在SortedSet的基础上拓展了很多用于方便查询的方法,在这里就不做赘述。
仔细看一下TreeSet的源码,首先是初始化和比较:
public TreeSet() {
this(new TreeMap<>());
}
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
没错,TreeSet的实现实际上并不是本身存在另类的代码,而是仅仅调用了TreeMap来进行存储,在TreeSet内部构建了一个NavigableMap的实例(TreeMap是NavigableMap的实现类),所有的增删操作都是对这个TreeMap进行的操作。
private transient NavigableMap<E,Object> m;
这时候我们有一个问题了,我们都知道Map集合是存在key/value结构的,既然TreeSet不存在key/value的概念,那么是怎么使用TreeMap进行存储的呢?
相信大家也都想到了,Set中的值不允许重复,而Map的key也不允许重复,那么直接将Set的值作为Map的key进行存储即可。
private static final Object PRESENT = new Object();
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return m.remove(o)==PRESENT;
}
public boolean addAll(Collection<? extends E> c) {
// Use linear-time version if applicable
if (m.size()==0 && c.size() > 0 &&
c instanceof SortedSet &&
m instanceof TreeMap) {
SortedSet<? extends E> set = (SortedSet<? extends E>) c;
TreeMap<E,Object> map = (TreeMap<E, Object>) m;
Comparator<?> cc = set.comparator();
Comparator<? super E> mc = map.comparator();
if (cc==mc || (cc != null && cc.equals(mc))) {
map.addAllForTreeSet(set, PRESENT);
return true;
}
}
return super.addAll(c);
}
③HashSet源码
相信看完TreeSet,大家心里也有了些B数,没错,HashSet的实现与TreeSet类似,HashSet也在内部有一个HashMap实例,增删操作依旧是对HashMap的操作。
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
这里还有一个有趣的地方,就是当我们在初始化时在后方再加一个boolean的参数时,其构建的就会默认为构建LinkedHashMap实例。
HashSet(int initialCapacity, float loadFactor, boolean dummy){
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
没错,从代码中可以看出来,这个boolean参数为true还是false都卵用没有,它只是用来标记的。
④LinkedHashSet源码
同样,LinkedHashSet也是对HashMap进行的操作,这时,我们刚才提到的方法就起了作用了,由于LinkedHashSet继承自HashSet,所以在初始化时,可以直接调用刚才讲到的HashSet的初始化方法来构建LinkedHashMap对象。
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
当然,除了这四个初始化方法之外,LinkedHashSet中也只有一个spliterator方法了。
@Override
public Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT | Spliterator.ORDERED);
}
所以我个人认为,相较于实用价值,LinkedHashSet的象征价值更高,因为它的所有功能在HashSet中都已经实现了,所以它的意义更大程度上在于让开发者用的更顺心,提高代码可读性。
⑤线程安全性
我们提到的这几个Set集合都不是线程安全的,它的线程安全性与其相对应的Map集合相关,同样我们可以使用Collections.synchronizedSet来实现线程安全的Set,但其也同样是以委托的方式添加synchronized锁,故效率较低。
3、Queue系集合
①Queue接口源码
其实我们在集合类中能够用到的队列集合不多,队列集合大多数都是在并发包下的阻塞队列中。我们先来看一下Queue的源码。
public interface Queue<E> extends Collection<E> {
boolean add(E e);
boolean offer(E e);
E remove();
E poll();
E element();
E peek();
}
可以看出,单纯Queue接口的源码中仅仅是定义了我们基于数据结构层次理解的队列的方法,而更多的拓展则是在Deque接口中。(并发包下的阻塞队列并不实现Deque,而是继承AbstractQueue,AbstractQueue再实现Queue,可以说并发包下的阻塞队列是更纯粹的队列实现)
public interface Deque<E> extends Queue<E> {
void addFirst(E e);
void addLast(E e);
boolean offerFirst(E e);
boolean offerLast(E e);
E removeFirst();
E removeLast();
E pollFirst();
E pollLast();
E getFirst();
E getLast();
E peekFirst();
E peekLast();
boolean removeFirstOccurrence(Object o);
boolean removeLastOccurrence(Object o);
boolean add(E e);
boolean offer(E e);
E remove();
E poll();
E element();
E peek();
boolean addAll(Collection<? extends E> c);
void push(E e);
E pop();
boolean remove(Object o);
boolean contains(Object o);
int size();
Iterator<E> iterator();
Iterator<E> descendingIterator();
}
如果说Queue是基于数据结构订立的接口,那么Deque就是基于现实的存储集合来订立的接口,它并不是传统的队列,而是定义了双向队列,我们可以从左端添加弹出,也可以从右端。
②LinkedList中的Deque实现
这时候我们想一下什么集合符合Deque的标准?
没错,LinkedList,从上面的图也可以看出,LinkedList也实现了Seque的接口,所以说,LinkedList实际上也可以作为一个双向队列。
我们也可以很简单的从LinkedList中找到它对Deque的接口的实现。
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
public E element() {
return getFirst();
}
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
public E remove() {
return removeFirst();
}
public boolean offer(E e) {
return add(e);
}
public boolean offerFirst(E e) {
addFirst(e);
return true;
}
public boolean offerLast(E e) {
addLast(e);
return true;
}
public E peekFirst() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}
public E pollFirst() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
public E pollLast() {
final Node<E> l = last;
return (l == null) ? null : unlinkLast(l);
}
public void push(E e) {
addFirst(e);
}
public E pop() {
return removeFirst();
}



